Stack Exploder: Scaling Node Infrastructure in a 1000+ Appchain Multiverse with Saga Edge Nodes
Saga is leading The Unblock movement, ushering in a new world where developers can build their web3 applications in as simple a way as possible. In the Unblock Manifesto, we highlighted how application developers have difficulty acquiring sufficient blockspace due to the need to manually stand up various parts of the infrastructure. Saga automates and trivializes the infrastructure for the developer by offering an Integrated Stack that automates launching on-demand blockspace.
An effective Integrated Stack requires the platform to automatically handle an immense amount of read, write and syncing requests. While existing infrastructure is sufficient for the status quo, it is not well equipped to handle demand of 1000+ appchains. The Saga Platform has many innovations that drive a breakthrough, but the most important component is a scalable back-end node infrastructure.
Today, we’re very excited to share our Saga Edge Node with the community.
Current Node Infrastructure Architecture
In a proof-of-stake blockchain, validators need to peer with each other to share consensus and other block production messages. At the same time, users need access to the validators to facilitate transactions to be included in blocks and read the latest state of the blockchain. If validators allow arbitrary connections from any of these sources, they open themselves to being intentionally or accidentally DDoSed. As a network, this is not acceptable because DDoSed validators do not participate in consensus and may halt the network.
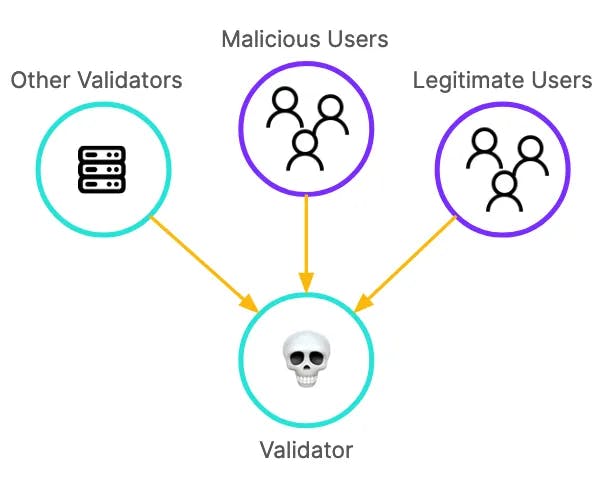
Directly exposing validator nodes may DDoS the validator
To solve this problem, networks employ a sentry (or proxy) node architecture. The validator node hides behind one or more sentry nodes. The validators only peer with their own sentry nodes, and all external stakeholders communicate to the validator through their corresponding sentry node.
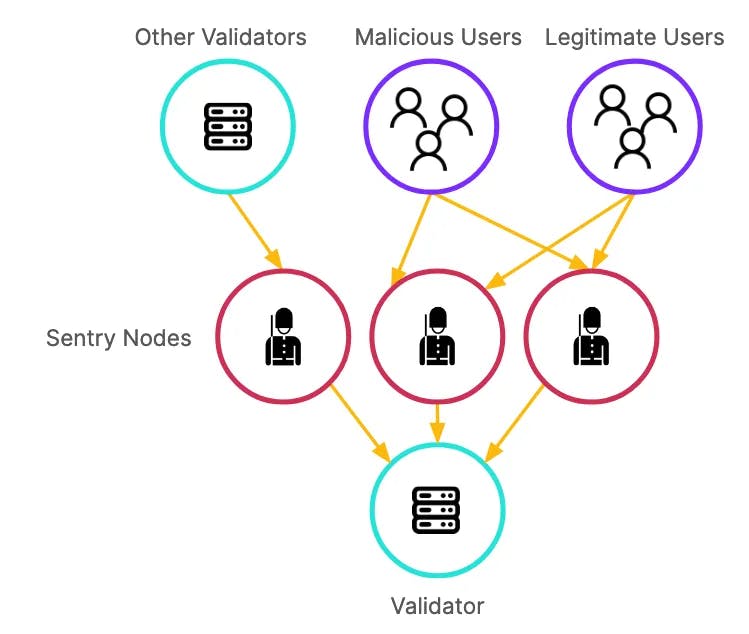
Example of a typical sentry node architecture to protect the validator
With any sudden increase in traffic, a sentry architecture is very effective in protecting the validator by offering 3 options to handle the requests:
- First, the sentry node can throttle access from users
- Second, the validator can choose to cut peering from the validator to (public) Sentry and allow block production to continue through their (private) Sentry connection to other validators
- Finally, the validator may stand up multiple public sentries to service the requests from users
In practice, validator operators generally employ option 3 by placing sentries in an autoscale group in the cloud that spins up new instances when the current instances are busy. While this type of architecture was sufficient for a small cluster of appchains, it quickly runs into scaling issues in a system where there are 1000s of blockchains.
Issues with the Sentry Node Architecture: Cost
There are three issues that compound with one another that make the existing sentry node architecture not suitable for Saga-scale.
First, a sentry node is usually a full node that does not sign blocks. This means that every sentry node is executing every transaction and block and verifying state transitions as if they were a validating node. The computation load of a sentry node is excessively high for what it needs to do. Assume each validator node costs 100 dollars per month to operate. Because a sentry node is the same cost as a validator node, if a validator chooses to operate 1 validator node and 2 sentry nodes, the cost per validator would be $300 (3x$100) per month.
Second, every validator needs to operate a sentry node to protect its external IP address. Using the $300 per month figure, a network with 100 validators requires $30,000 (100x$300) per month in node operating costs to be secure.
Finally, the sentry node is unique per chain. Because each sentry node is a full node of a particular network, the $30,000 cost per month needs to be multiplied by the number of chains. In a 1000 chain system, this would amount to $30,000,000 per month in aggregate node operating costs.
Obviously, the true aggregate cost is likely less than this figure since some validators will run zero or one sentry node. However, it is very evident why this kind of architecture is not viable for a system like Saga where there may be thousands of chains operated by the validators. From an architecture design perspective, prioritizing redundancy at the validator site-level instead of the network-level leads to over-provisioned and unused hardware.
Issues with the Sentry Node Architecture: Uncertainty and Inflexibility
Each sentry or full node is a generalized infrastructure component: it provisions hardware resources to handle all types of requests regardless of the needs of the network. In addition, different requests have bottlenecks from completely separate components of the infrastructure. For example, read requests may be bottlenecked by the number and quality of full nodes. Write requests may be bottlenecked by the mempool size and block generation speed. IBC requests may be bottlenecked by the relayer implementation, as well as block generation in the destination chain.
Finally, because of the generalized nature of sentry nodes, it takes a bit of time to spin up — each new sentry node needs to state sync and join the latest round of consensus before they are able to help scale the network. An effective node infrastructure should be able to dynamically spin up specific resources from the live traffic pattern of the network.
Introducing Saga Edge Node
Saga Edge Node makes node architecture more scalable by reducing infrastructure complexity and costs. The Saga Edge Node has the following qualities:
- A Saga Edge Node is incredibly cheap to run and does not break system consistency to have more than one running in parallel (and is therefore truly horizontally scalable)
- A Saga Edge Node can service as many Chainlets as needed
- A Saga Edge Node is able to act as a virtual node and actively manage requests in the validator infrastructure
Let’s explore how it works.
Making Saga Edge Nodes cheap to operate
A traditional sentry node is a full node, which means every sentry node is re-executing every transaction and updating their internal state.
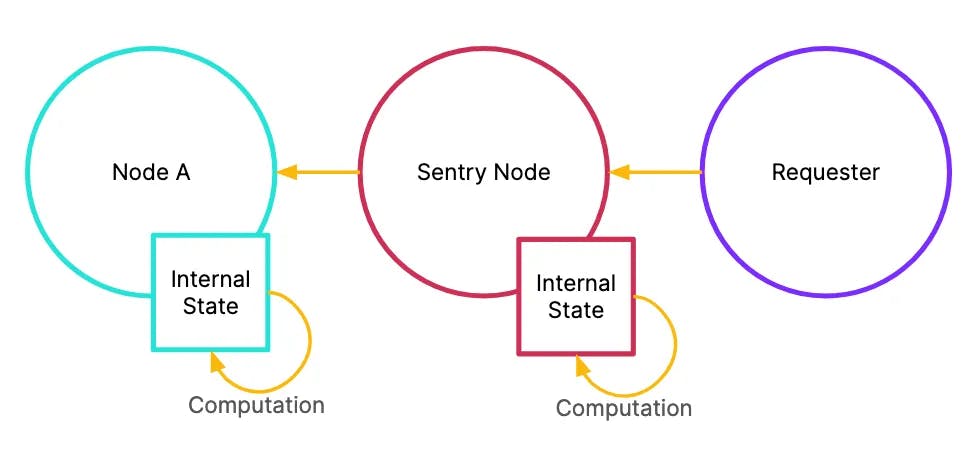
Traditional sentry nodes recompute the internal state to follow consensus
This amount of computation redundancy quickly accumulates costs to the node infrastructure. Instead, we can design the Edge Node to hold the IP address of the validator node and simply relay the requests across. With this, we push the redundancy from validator site-level to the network-level.
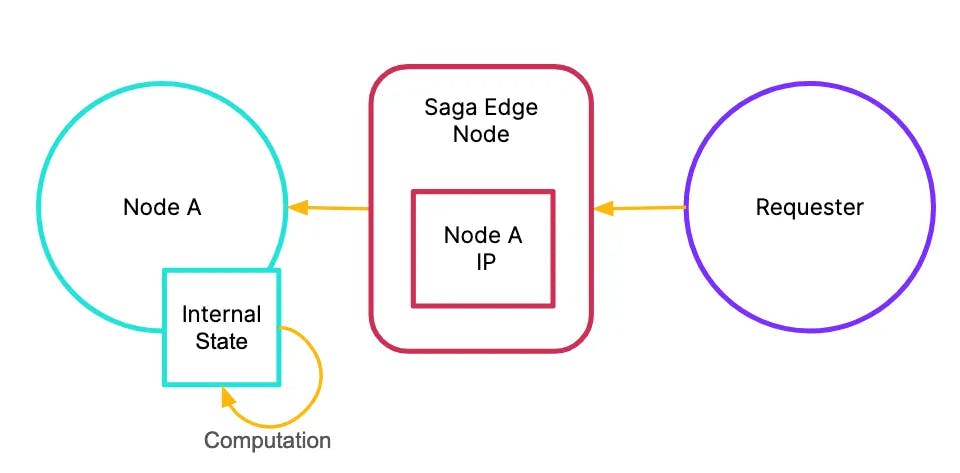
Saga Edge Nodes do not recompute the internal state
The Saga Edge Node therefore becomes incredibly cheap to operate because it is a simple lookup table and a passive relayer of connection requests from the requester to the validator node in question.
Multiplex Edge Node across multiple chains
We can improve the Saga Edge Node implementation by multiplexing requests for multiple chains into the same Edge Node. With this improvement, requests for all Chainlet activities can aggregate into the same Edge Node. The peering connections will automatically be relayed to the corresponding internal node.
How does this mechanically work? One issue is that because we have stripped out the part of the sentry node that syncs with the validator node, the Saga Edge Node is no longer aware of what individual requests are doing. We can model a solution similarly to how HTTP leaks Server Name Indication (SNI) in the TLS abstraction layer. When a requester sends any data to the Saga Edge Node, they can leak the chain_id field to route to the correct internal node.
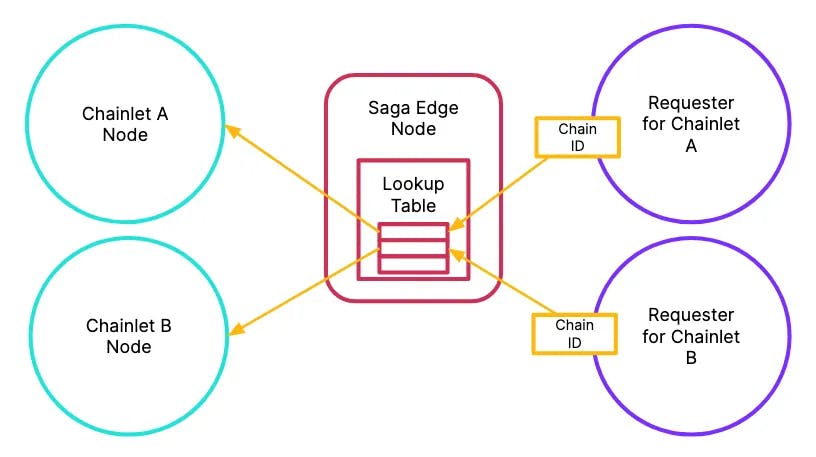
Edge nodes multiplex requests across all Chainlets into a single instance
With this implementation, validators and other node infrastructure providers can manage aggregate traffic across all Saga Chainlets, instead of worrying about standing up different sentry nodes for each individual chain.
Virtualize full nodes for active request management
While significantly improved from the existing sentry node architecture, the implementation has some issues. First, the requester must break the abstraction layer to leak chain_id information to the Saga Edge Node. Second, Edge Node is a passive participant in this system. Because the Edge Node has no knowledge about what requests are doing, all connection requests are automatically routed to the validator node. The peering connections are still one-to-one, meaning that if there are two requesters requesting the same thing, the validator node needs to make two separate peering connections.
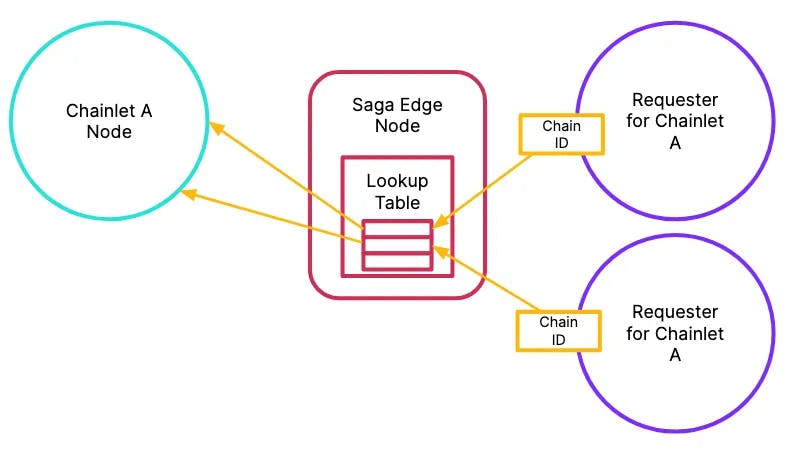
Two different requests for the same information leads to multiple peering requests on validator node
We can make the Saga Edge Node a more active participant in the network by forwarding certain metadata (such as head, round, step, etc) from the validator node to the Edge Node.
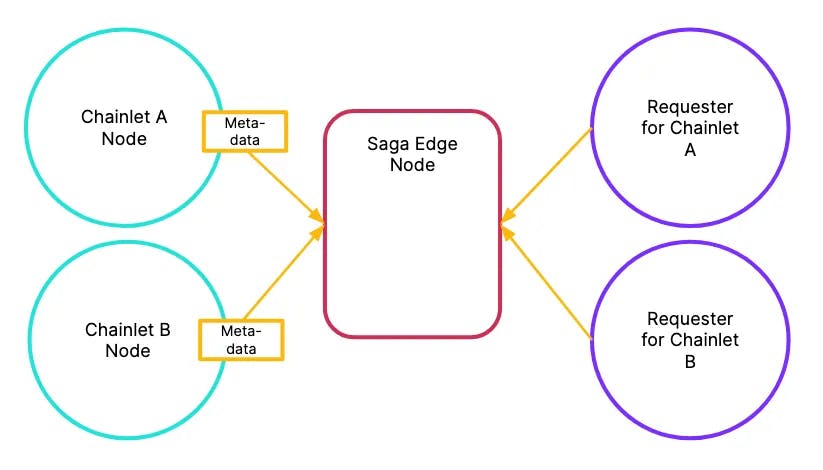
Forwarding appropriate metadata allows Edge Nodes to act like virtual full nodes
Using this metadata, the Saga Edge Node can appear like a virtual full node and peer directly with requesters. By peering directly, the validator nodes only need to peer with the Edge Node cluster, making operations much more efficient. This also removes the need for the requesters to leak the chain_id on requests.
Another benefit of this now active Edge Node is that the Edge Nodes can now begin redirecting certain requests such as state sync and PRC requests away from the validator nodes. This way, the validator node infrastructure can be stripped down to simply execute transactions and pass consensus messages between validators.
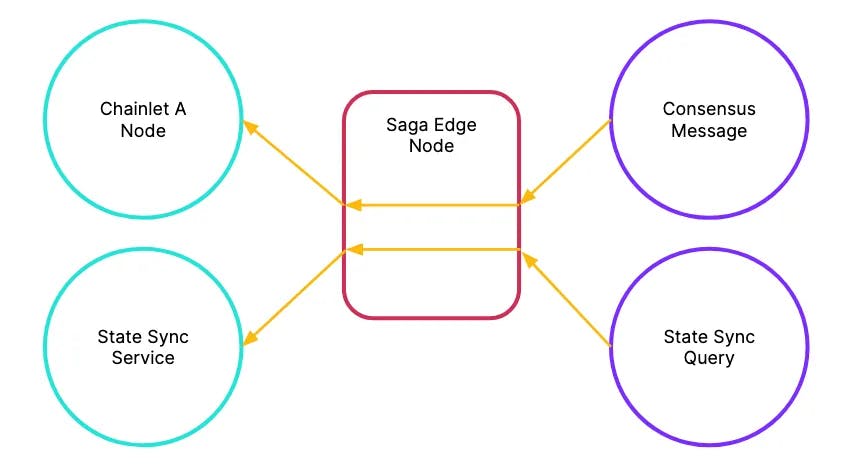
Saga Edge Nodes can actively redirect requests to appropriate internal resources and services
In fact, we can enable our Edge Node architecture to peer into various components within the Saga infrastructure to effectively provide back propagation to the end users. For example, when there are too many transactions in the mempool, the Edge Node could simply decline any further write requests. Alternatively, the Edge Node can peer into the IBC relayer queue and decline any further IBC messages based on the queue size. Edge Node back propagation is a powerful way to limit the resource demand to run a chainlet validator node. This is one way the Saga Platform can guarantee and deliver clearly defined SLA metrics to application developers and Chainlet customers, such as mempool size and IBC transaction limits.
Conclusion
A scalable node infrastructure is usually not a big focus for other blockchain ecosystems because the negative effects of an unoptimized node infrastructure are not immediately felt by the stakeholders. The accumulated cost of running redundant hardware indirectly contributes to expensive validator compensation. The uncertainty and inflexibility of the infrastructure indirectly contributes to inconsistent uptime and performance metrics.
The Saga Edge Node allows the infrastructure to horizontally scale purpose-driven components while keeping costs minimal. It is the latest innovation in the Saga Platform that allows application developers to unblock themselves through lower costs and predictable SLA and performance of their blockspace.